

CSVを開いて、ざっと中身を見て、必要なら集計に回す。
本来なら、それで終わるはずでした。
でも、今回のファイルは違いました。
Excelで開いた瞬間に動作が重い。表の見た目もどこかおかしい。見ているうちに、「これはただ重いだけじゃないな」と気づきました。行がずれて見える。列の対応が合わない。しかも、いちばん見たかったはずの最新設問の回答が見当たりません。
対象は、約5万行×約1,300列、サイズは数百MB級、文字コードはCP932。日本語の自由記述を多く含む、長年運用されたアンケートCSVでした。こういうファイルをExcelで“そのまま開く”のは、思っている以上に危ないです。この記事では、Excel上では壊れて見えたCSVを、Pythonで読み直して実体を確認し、誤削除を避けながら安全な分析用データへつなぎ直した過程をまとめます。Microsoft サポート Microsoft サポート
最初に起きていたのは、「列が多すぎる」ことではなく「表示が崩れる」ことだった
今回のCSVは横にかなり広く、設問が長年追加され続けた結果、列数は約1,300まで増えていました。
ただ、ここで最初に整理しておきたいのは、1,300列という数字自体はExcelの上限超過ではないということです。Excelのワークシート上限は 1,048,576行 × 16,384列 なので、1,300列は仕様上は十分入ります。つまり、今回の問題は単純な「列数オーバー」ではありませんでした。Microsoft サポート
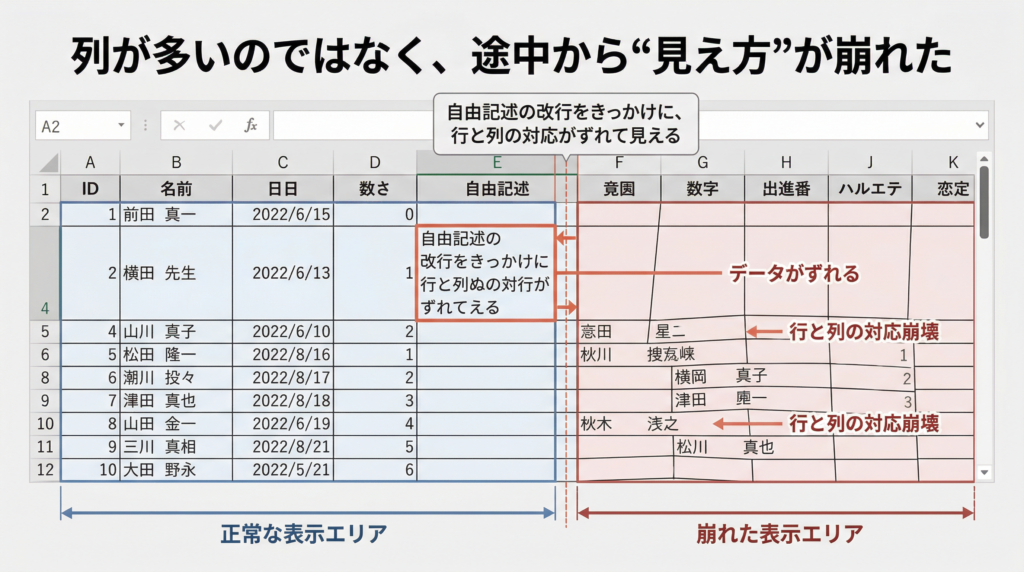
実際に起きていたのは、Excelで直接開いたときに、自由記述セル内の改行がうまく表示・解釈されず、行が途中からずれて見えたことでした。その結果、表全体の見た目が壊れ、末尾側の設問が見えなかったり、行と列の対応が崩れているように見えたりしました。
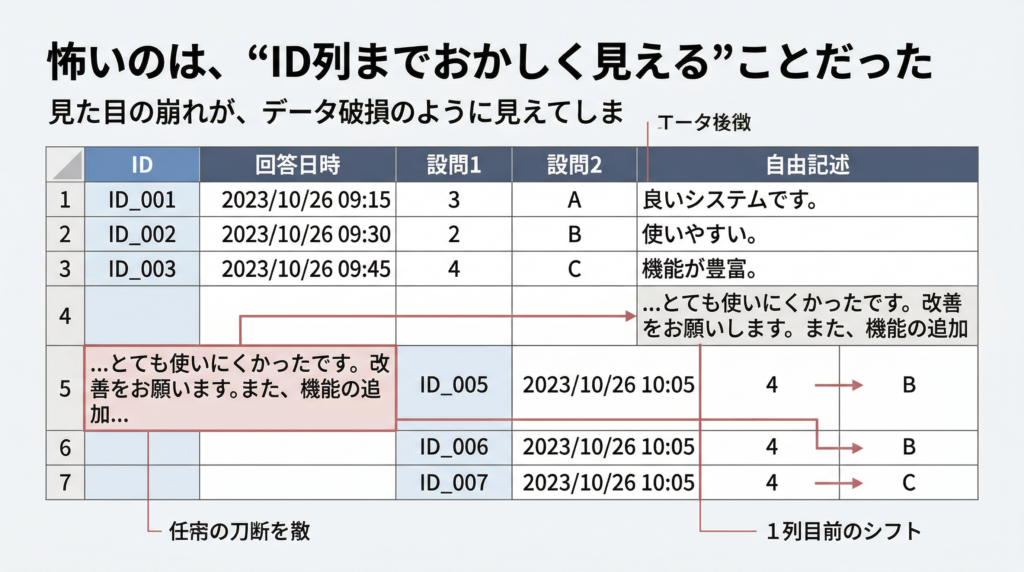
起きていたのはこういうことです。自由記述欄に入力された改行を、ExcelがCSVの「次の行の始まり」と誤認した。その結果、本来1件のデータが画面上では複数行に分かれて表示され、以降の列が右にずれて見えた。ファイルが壊れていたのではなく、Excelの解釈がずれていたわけです。見た目だけを信じると、「壊れた行を落とせばいいのでは」と考えたくなります。でも、それが今回もっとも危ない落とし穴でした。Microsoft サポート
壊れていたのはCSVではなく、Excel上の“見え方”だった
結論から言うと、元のCSVは少なくともCSVとして不正とは言えませんでした。
平たく言うと、自由記述欄に「途中で改行を含む文章」が入っていただけです。CSVでは、こういう値をダブルクォートで囲うことで1セルとして扱います。pandasはこのルールに沿って正しく読めます。ところがExcelの直接オープンでは、このクォートされた改行を見落として「新しい行が始まった」と判断してしまうことがある。だから、崩れて見えました。pandas 公式ドキュメント
技術的に補足すると、CSVの代表的仕様である RFC 4180 では、カンマ・改行・ダブルクォートを含むフィールドはダブルクォートで囲うべきとされています。つまり、自由記述の中に改行があること自体は異常ではなく、正しくクォートされていれば仕様上まったくあり得る挙動です。RFC 4180
たとえば、次のような自由記述は、CSVとして自然な内容です。
“雰囲気をじっくり味わうことができました。
とても印象に残る内容でした。”
この改行は「レコードが壊れている」わけではなく、1つのセルの中に入っている改行です。テキストエディタや一部の表計算ソフトで見ると複数行に見えますが、CSVパーサはそれを1フィールドとして扱うべきです。RFC 4180
pandasで読み直すと、“消えた最新回答”は戻ってきた

そこで、Excel上の見た目ではなく、CSVパーサとして信頼できるツールで読み直しました。
使ったのは pandas の read_csv() です。pandas はクォート文字、ダブルクォートの扱い、エンコーディング指定などを明示的に持っていて、CSVを“表っぽく見せるツール”ではなく、CSVとして解釈するツールとして振る舞います。pandas 公式ドキュメント
import pandas as pd
df = pd.read_csv("data.csv", encoding="cp932", low_memory=False)
print(df.shape) # 行数 × 列数
print(df.columns[-5:]) # 末尾列が存在するか
print(df.isnull().mean().tail(10)) # 末尾列の欠損率この3行を見るだけでも、かなりのことが分かります。
想定した件数・列数で読めているか。最新設問に相当する末尾列が存在しているか。末尾列が全部 NaN になっていないか。
Excel上では「最新回答が消えた」と見えていても、pandas上では末尾列がちゃんと存在し、自由記述の改行も1セルとして保持されていることがあります。今回の本質は、まさにそこでした。pandas 公式ドキュメント
ここで大事なのは、物理行数と論理レコード数は一致しないことがあるという点です。セル内改行を含むCSVでは、ファイル上の行数が多く見えても、パーサ上は正しい件数のレコードとして解釈されます。なので、テキスト上で「行が増えているように見える」からといって、すぐにデータ破損と判断してはいけません。RFC 4180 pandas 公式ドキュメント
「崩れて見える行を削除する」は、やってはいけない
この経験でいちばん強く感じたのは、Excelで崩れて見えた行を、そのまま“壊れた行”だと決めつけて削除してはいけないということです。
もしその判断が間違っていたら、削除しているのは不正レコードではなく、自由記述を丁寧に書いてくれた正常な回答かもしれません。しかも、自由記述が多い回答者ほどセル内改行を含みやすい。つまり、安易に落とすと、熱量の高い回答ほど分析対象から消えてしまう可能性があります。
今回の“禁じ手”は、単なるデータクレンジングの失敗ではありませんでした。
危なかったのは、Excelの表示の癖を、元データの破損だと誤認してしまうことそのものです。だからこの記事でいちばん伝えたい教訓は、「壊れた行を削除するな」よりも、むしろ「Excelで崩れて見えただけのデータを削除するな」です。Microsoft サポート RFC 4180
Excelは便利。でも、CSVの真偽判定には向いていない
もちろん、Excelそのものが悪いという話ではありません。
軽いCSVを目で確認するには、今でもExcelは便利です。ただ、Microsoft自身も案内しているように、CSVの扱いには「直接開く」方法と「データ > テキスト/CSVから」で取り込む方法があります。さらに、大きすぎるデータセットについては、Get Data / Power Query を使うことが勧められています。つまり、Excel自身も「CSVをダブルクリックして見る」ことを、いつでも最良の方法とはしていません。Microsoft サポート Microsoft サポート
要するに、ExcelはCSVの厳密検証ツールではないということです。
表示確認には便利ですが、CP932・大容量・自由記述・セル内改行・多数列といった条件が重なると、「見た目が正しいかどうか」と「データが正しいかどうか」がズレます。今回のようなケースでは、Excelは入口の確認には使えても、真偽判定の最後の拠り所には向いていませんでした。Microsoft サポート
CSVを受け取った直後にやるべきこと
今回のような事故は、Excelで開いた瞬間ではなく、ファイルを受け取った時点で半分防げます。
ポイントは、「まず開く」のではなく、まず診断することです。
特に日本の業務システム由来のCSVでは、UTF-8ではなくCP932のことが珍しくありません。しかも、アンケートや申請フォームのエクスポートは、自由記述欄や設問追加の積み重ねで、行数も列数も想像以上に大きくなりがちです。そんなファイルに対して、いきなりExcelを最初の受け皿にするのは危険です。Python 日本語ドキュメント Microsoft サポート
私が実務でまず見るのは、ファイルサイズ、文字コード候補、列数の多さ、自由記述やセル内改行の気配の4つです。この段階で危険信号が2つ以上出ているなら、そのCSVは「Excelでとりあえず見るファイル」ではなく、pandasで安全に受けるファイルだと考えたほうがいいです。
文字コード推定に chardet を使うことはできますが、返ってくるのは確定値ではなく推定と信頼度です。なので、実際には pandasで少量読みして確かめるところまでセットで見るのが実務向きです。chardet ドキュメント pandas 公式ドキュメント
順番としては、こんなイメージです。
サイズを見る → 文字コード候補を取る → 少量読みで構造を確認する → 全件読みで shape・末尾列・NULL率を見る
ここで大事なのは、いきなり型推論に頼らないことです。
最初に守るべきなのは「型」よりも「構造」です。CSVは型が多少ずれていても後で直せます。でも、文字コードや quoted newline を誤って開いてしまうと、そもそも正しい表に戻れなくなります。pandas 公式ドキュメント RFC 4180
実務で使っている、pandasの診断テンプレート
以下は、CP932・セル内改行・大量列を想定した診断用テンプレートです。
考え方はシンプルで、最初から「正しく型をつけて読む」ことより、壊さず確認することを優先するようにしています。
import os
import chardet
import pandas as pd
def diagnose_csv(filepath):
"""
大規模・日本語CSVを安全に診断するための実務テンプレート
"""
print("=== 1. ファイル基本情報 ===")
# ファイルサイズ確認
size_mb = os.path.getsize(filepath) / 1_048_576
print(f"ファイルサイズ: {size_mb:.1f} MB")
# 文字コードを推定(確定ではなく推定)
with open(filepath, "rb") as f:
raw = f.read(20000)
detected = chardet.detect(raw)
print(f"推定文字コード: {detected['encoding']}")
print(f"信頼度: {detected['confidence']:.0%}")
print()
print("=== 2. 少量読みで安全確認 ===")
candidate_encodings = ["utf-8-sig", "utf-8", "cp932"]
chosen_encoding = None
df_peek = None
for enc in candidate_encodings:
try:
df_peek = pd.read_csv(
filepath,
encoding=enc,
nrows=20,
dtype=str
)
chosen_encoding = enc
print(f"少量読み成功: {enc}")
break
except Exception as e:
print(f"少量読み失敗: {enc} -> {e}")
if chosen_encoding is None:
raise ValueError("読めるエンコーディング候補が見つかりませんでした。")
print(f"先頭20行の shape: {df_peek.shape}")
print("先頭5列:", df_peek.columns[:5].tolist())
print("末尾5列:", df_peek.columns[-5:].tolist())
print("\n自由記述っぽい列(簡易推定):")
str_cols_peek = df_peek.select_dtypes(include="object").columns.tolist()
free_text_candidates = []
for col in str_cols_peek:
series = df_peek[col].dropna().astype(str)
if len(series) == 0:
continue
avg_len = series.str.len().mean()
if avg_len > 20:
free_text_candidates.append((col, avg_len))
for col, avg_len in free_text_candidates[:10]:
print(f" - {col}(平均 {avg_len:.1f} 文字)")
print()
print("=== 3. 全件読み ===")
df = pd.read_csv(
filepath,
encoding=chosen_encoding,
low_memory=False
)
print(f"全件 shape: {df.shape}")
print("末尾5列:", df.columns[-5:].tolist())
print("\n末尾10列のNULL率:")
print(df.isnull().mean().tail(10))
print()
print("=== 4. 型のざっくり把握 ===")
print(df.dtypes.value_counts())
num_cols = df.select_dtypes(include="number").columns.tolist()
str_cols = df.select_dtypes(include="object").columns.tolist()
print(f"数値列: {len(num_cols)}列")
print(f"文字列列: {len(str_cols)}列")
print()
print("=== 5. セル内改行の確認 ===")
newline_cols = []
for col in str_cols:
series = df[col].dropna().astype(str)
if len(series) == 0:
continue
has_newline = series.str.contains(r"\r|\n", regex=True).any()
if has_newline:
newline_cols.append(col)
print(f"セル内改行あり列: {len(newline_cols)}")
for col in newline_cols[:20]:
print(f" - {col}")
return dfこのテンプレートの考え方は単純です。
最初は「賢く読む」より「壊さず読む」。そのあとで必要に応じて型整理や高速処理に進む。CSVの入口で失敗すると、その後の処理が全部不安定になります。逆に、入口さえ安定していれば、その先はかなり自由です。pandas 公式ドキュメント chardet ドキュメント
読み込みと分析は、同じツールでやらないほうが安定する
今回の経験で見えてきたのは、「読み込む」と「分析する」は、同じツールでなくていいということでした。
むしろ、役割を分けたほうが安定します。
CP932 のような日本語環境のCSVや、自由記述を含む quoted newline ありのCSVは、入口でつまずきやすいです。一方で、いったん正しい表にできてしまえば、その後の集計や分析は、より高速なツールに渡したほうが効率がいい。つまり、入口の安定性と、分析フェーズの速度は分けて考えるのが現実的です。pandas 公式ドキュメント Polars 公式ドキュメント readr 公式ドキュメント
pandas・Polars・Rはどう使い分けるのがよさそうか
今回のような CP932 / セル内改行 / 大量列 を含むCSVを前提に、実務寄りに整理するとこんな感じです。
| ツール | 読み込みの安定性 | 速度 | 前処理向き | 集計・分析向き | 使いどころ |
| pandas | 高い | 中程度 | ◎ | ○ | 最初の受け皿。CP932やquoted newlineを含むCSVの確認・診断に向く |
| Polars | CSV直接受けはやや慎重 | 速い | ○ | ◎ | pandasで受けた後の高速処理。Parquet経由が安定 |
| R / readr | 比較的高い | 中程度 | ○ | ○ | Rで入口から扱うなら有力 |
| R / data.table::fread | CP932入口は慎重 | とても速い | ○ | ◎ | UTF-8化後の高速処理に向く |
ひとことで言うなら、
pandasで安全に受けて、Parquetに変えて、そのあとPolarsやRに渡す。
この役割分担が、いちばん事故が少なくて、しかも速いです。Apache Parquet Polars 公式ドキュメント
実務では「CSVを受ける役」と「高速に回す役」を分ける
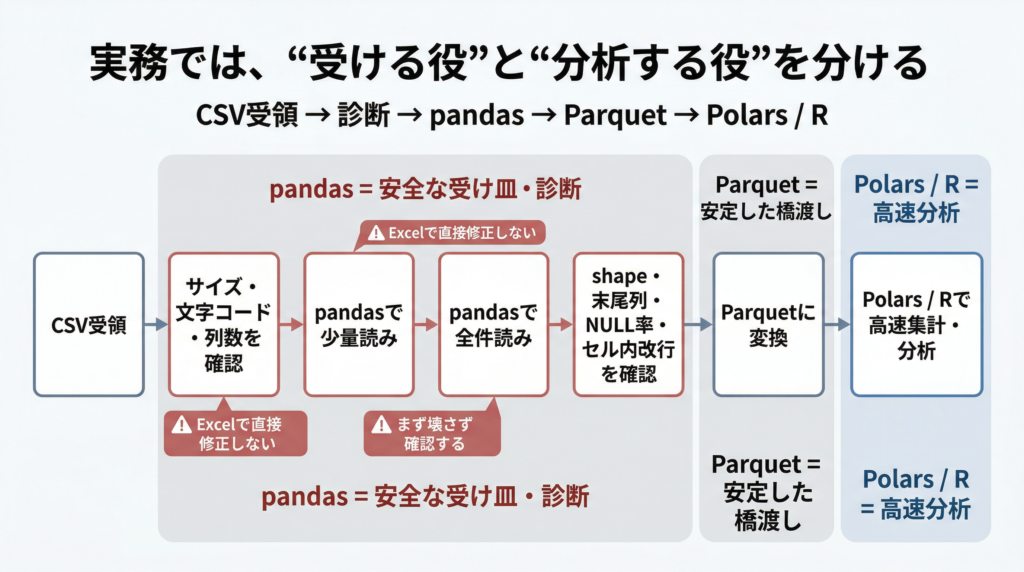
たとえば、流れとしてはこんな感じです。
- pandas で CSV を安全に読む
- shape・末尾列・NULL率・セル内改行列を確認する
- 問題がなければ Parquet に変換する
- 重い集計や分析は Polars や R に渡す
import pandas as pd
import polars as pl
df = pd.read_csv("data.csv", encoding="cp932", low_memory=False)
df.to_parquet("data.parquet")
df_pl = pl.read_parquet("data.parquet")Parquet は列指向で、保存効率と取得効率に優れ、分析用途に向いたフォーマットです。CSVを人間の受け渡し用フォーマット、Parquetを機械の分析用フォーマットと考えると、かなり整理しやすくなります。Apache Parquet
新しいCSVを受け取ったとき、最初に確認しておくこと
最後に、実務でそのまま使える形にすると、確認項目はこんな感じです。
受領直後のチェック
- [ ] ファイルサイズはどれくらいか(目安: 50MB超なら要警戒)
- [ ] 文字コードは UTF-8 か、CP932 か、それ以外か
- [ ] 日本語CSVか
- [ ] 自由記述欄がありそうか
- [ ] 長期運用データで列数が増えていそうか
- [ ] アンケート、問い合わせ、申請、備考欄など、セル内改行が入りやすいデータか
少量読みのチェック
- [ ] nrows=20 などで少量読みできるか
- [ ] 列数は想定通りか
- [ ] 先頭列・末尾列の名前は自然か
- [ ] 末尾列が途中で欠けていないか
- [ ] 自由記述っぽい列が見えるか
全件読み後のチェック
- [ ] df.shape で行数・列数が想定通りか
- [ ] df.columns[-5:] で末尾列が存在するか
- [ ] df.isnull().mean().tail(10) で末尾列が丸ごと欠損していないか
- [ ] df.dtypes.value_counts() で極端な型崩れがないか
- [ ] セル内改行を含む列を把握できているか
Excelを使うときの判断基準
- [ ] 開くのが異様に遅くないか
- [ ] 行や列が途中からずれて見えていないか
- [ ] 最新設問や末尾列が見えなくなっていないか
- [ ] 想定件数より少なく見えていないか
- [ ] おかしいと思ったら、Excel内修正に進まず pandas に切り替えたか
このチェックリストのポイントは、「開いてから判断する」のではなく、「壊さず確認する」ことを先に置くところです。今回のようなCSVでは、この順番がいちばん効きました。pandas 公式ドキュメント Microsoft サポート
よくある質問
Q1. Excelで崩れて見えたら、CSVファイル自体が壊れているのでしょうか?
必ずしもそうではありません。今回のように、自由記述欄のセル内改行をExcelがCSVの次の行と誤認して、行や列がずれて見えることがあります。見た目はかなり深刻ですが、実際にはCSV自体は正しく、pandasで読み直すと問題なく復元できるケースがあります。
まず疑うべきなのは「ファイル破損」ではなく、Excelの解釈がずれていないかです。
Q2. 5万行×1,300列なら、Excelの上限を超えたのが原因ではないのですか?
それも違います。Excelの上限は 1,048,576行 × 16,384列 なので、5万行×1,300列 は上限内です。
つまり今回の問題は「列数が多すぎて開けない」という話ではなく、セル内改行を含むCSVをExcelがきれいに表示できなかったことが本質です。
Q3. こういうCSVは、最初からPythonのpandasで開くのがいちばん安全ですか?
はい。特に今回のような CP932・大規模・自由記述あり のCSVでは、最初に pandasで安全に診断しながら読む のが最も実務的です。
いきなりExcelで編集し始めるより、まず read_csv() で構造を確認し、行数・列数・末尾列・欠損率を見たほうが事故が起きにくくなります。
Q4. それでもExcelで確認したい場合はどうすればいいですか?
「直接ダブルクリックで開く」のではなく、インポート機能やPower Query経由で取り込むほうが安全です。
ただし、今回のような 数百MB級・自由記述あり・CP932 のCSVでは、Excelはあくまで「ざっと眺める道具」と考えたほうが無難です。
真偽判定や正式な読み込みはpandas側で行う、という役割分担が安定します。
Q5. CP932かどうかは、どうやって確認すればいいですか?
実務では、まずファイルの出どころを確認しつつ、必要に応じて chardet などで推定します。
ただし、文字コード推定はあくまで補助です。最終的には、utf-8-sig、utf-8、cp932 などの候補で少量読みを試し、文字化けせず、列構造が崩れず、末尾列まで正しく読めるかで判断するのが確実です。
Q6. 最初に型を調べたいときは、どう進めるのが良いですか?
最初の段階では、型を厳密に当てにいかないほうが安全です。
まずは nrows=20 などで少量だけ読み、必要なら dtype=str を使って、構造確認を優先します。
いきなり型推論に頼ると、列ずれや文字コードの問題があるときに、むしろ状況が見えにくくなることがあります。
実務では、
- 少量読みで構造確認
- 全件読み
- その後に型や前処理を整理
の順が安定です。
Q7. low_memory=False はなぜ付けたほうがいいのですか?
大きいCSVを読むとき、pandasは内部的に分割しながら型推論を進めることがあります。
その結果、列によっては途中で型の解釈が揺れて、警告や扱いづらさが出ることがあります。low_memory=False を付けるとメモリ使用量は増えやすくなりますが、少なくとも「まず壊さず読む」段階では挙動が安定しやすいので、診断用途では相性が良い設定です。
Q8. Polarsのほうが速いなら、最初からPolarsで読めばよいのでは?
速度だけ見れば魅力はありますが、今回のような CP932・セル内改行・複雑なCSV では、まずpandasで安全に受けるほうが安定します。
実務では、
- 読み込みと診断は pandas
- 高速な集計・分析は Polars
と分けるのが扱いやすいです。
つまり、「読み込む役」と「分析する役」を分けるのがポイントです。
Q9. Rで扱う場合も、やはり最初はpandas経由のほうがいいですか?
ケースによりますが、CP932で不安がある大規模CSV なら、pandasで一度安全に読み、ParquetやUTF-8 CSVに変換してからRへ渡す流れはかなり実務向きです。
Rで直接読むなら readr::read_csv(..., locale = locale(encoding = "CP932")) は有力ですが、処理の安定性を優先するなら、やはり最初の受け皿をpandasに置く構成は強いです。
Q10. 崩れて見える行だけ削除してしまえば早いのでは?
これはかなり危険です。
今回のようなケースでは、崩れて見える原因はデータそのものの破損ではなく、表示や解釈のズレである可能性があります。
そのため、Excel上で「おかしく見える行」を削除してしまうと、実際には正常な回答、しかも自由記述をしっかり書いてくれた重要な回答を落としてしまうことがあります。
見た目だけで削るのではなく、まずpandasで正しく読めるかを確認するべきです。
Q11. 新しいCSVを受け取ったとき、最初に何を見ればいいですか?
実務では、最初に次の4点を見るだけでもかなり違います。
- ファイルサイズはどのくらいか
- 文字コードはUTF-8か、CP932か
- 列数は多いか、自由記述列はありそうか
- Excelで開いて表示が怪しくないか
この時点で 「大きい」「日本語CSVっぽい」「自由記述がある」「Excel表示が怪しい」 が揃ったら、早めにpandasへ切り替える判断がしやすくなります。
Q12. 結局、いちばん実務的な流れはどれですか?
迷ったら、次の流れがいちばん安定します。
- CSVを受け取る
- ファイルサイズ・文字コード候補・列数の雰囲気を確認する
- pandasで少量読みして構造を確認する
- pandasで全件読みする
shape、末尾列、NULL率、セル内改行の有無を確認する- 問題なければParquetへ変換する
- その後の高速集計はPolarsやRに渡す
つまり、入口はpandas、以降は用途に応じて高速系ツールへ渡す、という形です。
まとめ:Excelで崩れて見えても、まず疑うべきは“表示”のほうだった
今回のCSVは、Excelでは崩れて見えました。
でも、だからといって元データが壊れているとは限りませんでした。実際には、セル内改行を含む正当なCSVを、Excelの直接オープンがうまく扱えず、表示上の混乱が起きていた可能性が高かったわけです。
だから、同じようなファイルに出会ったら、まず疑うべきは「ユーザーが変なデータを入れたこと」でも「CSVが壊れていること」でもありません。
いま見えているその表示が、ほんとうにデータの実体を表しているのか。
まずそこを疑ったほうがいい。
Excelで崩れて見えたから削除する。
それは、いちばん避けたい判断でした。
まずは pandas で読み直す。
正しく読めたら Parquet に変える。
高速処理はその先で Polars や R に渡す。
たぶんこれが、日本語・大容量・自由記述ありCSVに対して、いちばん現実的で事故の少ないやり方です。RFC 4180 pandas 公式ドキュメント Apache Parquet
参考リンク(日本語中心)
日本語で読める公式資料
- テキスト(.txt または .csv)ファイルのインポートまたはエクスポート
https://support.microsoft.com/ja-jp/office/テキスト-txt-または-csv-ファイルのインポートまたはエクスポート-5250ac4c-663c-47ce-937b-339e391393ba - Excel の仕様と制限
https://support.microsoft.com/ja-jp/office/excel-の仕様と制限-1672b34d-7043-467e-8e27-269d656771c3 - Excel グリッドに対してデータ セットが大きすぎる場合の対応
https://support.microsoft.com/ja-jp/office/excel-グリッドに対してデータ-セットが大きすぎる場合の対応-976e6a34-9756-48f4-828c-ca80b3d0e15c - Python 日本語ドキュメント: codecs
https://docs.python.org/ja/3/library/codecs.html
公式原典(日本語版が乏しいもの)
- pandas read_csv
https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html - RFC 4180
https://www.ietf.org/rfc/rfc4180.txt - chardet usage
https://chardet.readthedocs.io/en/latest/usage.html - Polars read_csv
https://docs.pola.rs/py-polars/html/reference/api/polars.read_csv.html - Polars quoted newline issue
https://github.com/pola-rs/polars/issues/19078 - readr read_delim
https://readr.tidyverse.org/reference/read_delim.html - data.table fread
https://rdatatable.gitlab.io/data.table/reference/fread.html - Apache Parquet
https://parquet.apache.org/