データサイエンスの独学に限界を感じる理由とは?オンライン講座の落とし穴と2026年の実践的学習法

近年、リスキリングの機運が高まり、CourseraやedX、gaccoといったMOOC(大規模公開オンライン講座)でデータサイエンスを学ぶ人が急増しました。しかし、意気揚々と学習を始めたものの、「このままで仕事に使えるのか?」「専門書の内容が頭に入ってこない」と、独学の限界を感じている方が後を絶ちません。
実は、2025年現在のデータサイエンス教育市場において、単なる知識のインプット(リスナー)から、実務への適用能力(プレイヤー)への転換はかつてないほど難しくなっています。
今回は、独学者が陥る「3つの壁」を解体し、最短で即戦力になるための「ハイブリッド型教育」という選択肢について解説します。
1. なぜ動画講座だけでは「即戦力」になれないのか?
世界最高峰の講義を数千円、あるいは無料で見られるMOOCは素晴らしいツールです。しかし、そこには実務家への道を阻む「構造的な落とし穴」が存在します。
① 圧倒的な「継続」の難しさと孤独感
完全オンラインのオンデマンド形式は自由な反面、極めて高い自己規律が求められます。統計によると、MOOCの完走率は一般的に10%以下と言われています。一人で画面に向かい続ける「孤独な学習」は、モチベーションを維持する外的な強制力がなく、多くの人が途中で挫折してしまう最大の原因です。
② 「知識(Know-how)」は得られても「スキル(Do-how)」が欠ける
Pythonの文法や統計学の用語を覚えても、それだけでは不十分です。実務で求められるのは、以下のような暗黙知です。
- プロジェクトをどう計画し、進行するか?
- 汚いデータ(ノイズ)をどうクレンジングするか?
- 多様なチームメンバーとどう意思疎通するか?
これらの「ソフトスキル」は、一方通行の講義を聴くだけでは決して身につきません。
③ 成長を止める「フィードバックの欠如」
学習者の知識更新は、ベイズの定理によって以下のようにモデル化できます。$$P(\theta | D) \propto P(D | \theta) P(\theta)$$
ここで、$\theta$ はあなたのスキル水準、$D$ は得られたフィードバック(データ)です。独学の場合、得られる $D$ が自己完結的であるため、事後分布 $P(\theta | D)$ が誤った方向に収束したり、成長が停滞したりするリスクがあります。現役のプロによる客観的な指摘があって初めて、あなたのスキルは「実務レベル」へと正しく更新(Update)されるのです。
2. 独学の限界を突破する「ハイブリッド型トレーニング」
独学の限界を感じている層に向けて、2025年現在、最も注目されているのがオンラインの利便性と対面指導の強制力を融合させた「ハイブリッド型教育」です。
特にイスラエル流の教育メソッドを導入したプログラム(Wawiwaなど)では、従来のスクールとは一線を画すアプローチが取られています。
一般的なMOOCとハイブリッド学習の比較
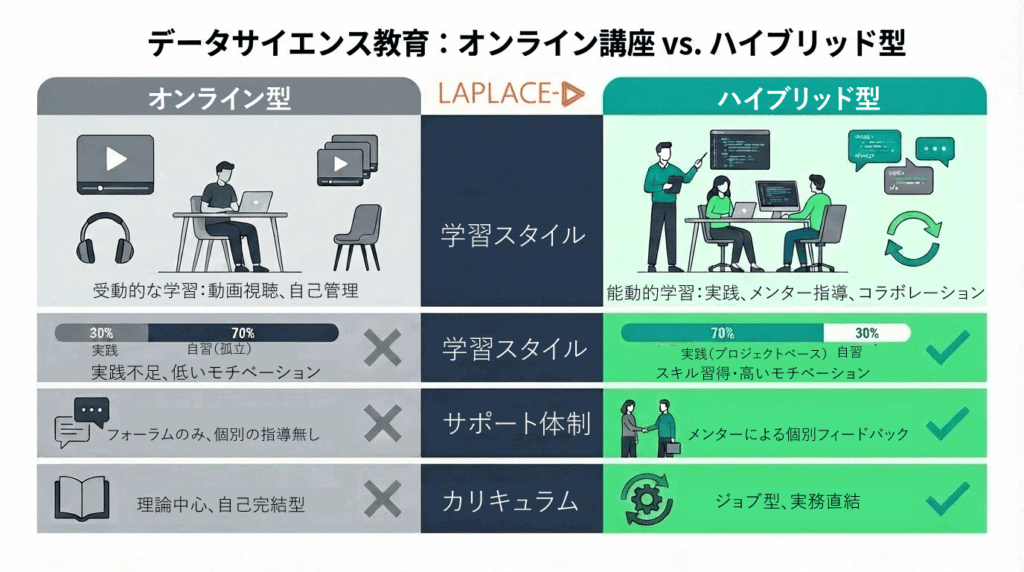
| 比較項目 | 一般的なMOOC (Udemy等) | ハイブリッド型学習 (ORLAB等) |
|---|---|---|
| 学習形式 | 完全オンライン(オンデマンド) | ライブ講義 + 個別伴走指導 |
| 実践比率 | 座学・聴講が中心 | 実践が7割(ハンズオン重視) |
| サポート | 基本は自己解決 | 専属メンターによる直接添削 |
| 求人ニーズ | グローバル共通の基礎 | 地域の求人ニーズに特化 |
| 経済的支援 | 自己負担 | 専門実践教育訓練給付金(最大80%) |
単に「聴く」だけでなく、現役のプロからフィードバックを受けながら、SQL・Python・Power BIを駆使して「実案件に近いプロジェクトを作る」環境に身を置くことが、最短ルートとなります。
3. 2025年版・失敗しないための「講座選び」チェックリスト
溢れる情報に流されないよう、以下のポイントをチェックしてから投資先を決めましょう。
- [ ] アウトプットの機会があるか?:単なるクイズではなく、ポートフォリオ(成果物)が作れるか。
- [ ] 生成AI(Generative AI)を使いこなすカリキュラムか?:ChatGPTやClaudeを「分析パートナー」として活用する手法を教えているか。
- [ ] 「伴走型」のサポートはあるか?:エラーで詰まった時、24時間以内に人間からの回答が来るか。
- [ ] 給付金制度の対象か?:経済産業省の「Reスキル講座」などに認定され、受講料の還付があるか。
4. 【厳選】独学を補完するリソースと「毒出し」の視点
もしあなたがまだ独学を続けたい、あるいは基礎を固めたいなら、以下のリソースを推奨します。
推奨リソース3選
- Coursera「Google Data Analytics」: 実務の全体像を掴む世界標準。
- 『AI・データ分析プロジェクトのすべて』: 技術ではなく「ビジネス」の進め方を説く必読書。
- 統計検定の関連書籍: 表面的なツール操作ではなく、データ分析の「数学的根拠」を養う。
【おまけ】AI関連の「情報洪水」への毒出し
昨今のAI書籍には、あえて厳しい目を向ける必要があります。 どの本も「AIとは」「AIの歴史」というお約束のページから始まりますが、実務家を目指すならこれらは不要です。人工知能学会ですら「AIに厳密な定義はない」と言っているのですから、導入は「定義なし!」の一行で十分でしょう。
「数式を使わない!」と謳う入門書よりも、あえて数理的に厳密な本を、ChatGPTなどのAIコーディング支援を使いながら読み解くほうが、2025年流の賢い学習法と言えます。
結論:情報の「海」を泳ぎ切り、自立するために
データサイエンスの学習過程は、統計学における「過学習(Overfitting)」に似ています。教材というトレーニングデータにだけ最適化され、未知のビジネス課題(テストデータ)に対応できない状態。これが「独学の限界」の正体です。
この汎化誤差を最小化するためには、現実の「ノイズ」を含んだ実践環境と、プロによる「正則化(フィードバック)」が必要です。
もしあなたが今の学習に停滞を感じているなら、単なる「リスナー」を卒業し、実践とフィードバックがある「環境」を選んでみてください。それが、データサイエンティストとしてのキャリアを切り拓く唯一の鍵となります。
