

はじめに
前回の記事で盛大に脱線しまくったため、今回は本題となる、Bing SearchがGoogle Searchに勝てない3つの要素を分析いたします。今回こそは脱線しない事を祈りつつ、記事をご一読下さい
モラル問題

少し不謹慎ではありますが、技術の革新(特にB2C)はエロとともに普及爆発が発生します。検索エンジンは、理由は不明ですが、不謹慎な動画、画像のINDEXも構築されており、合法、非合法を問わず、今夜のおかずを必ず紹介してくれます。
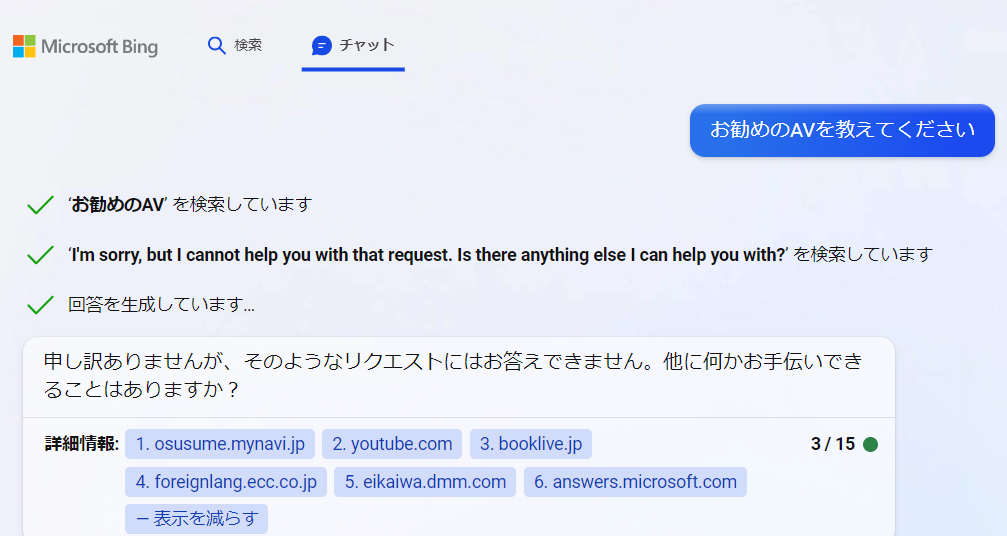
新しいBing Searchgは、Chatインターフェースであること、生成AIであること、AIに変なモラルを求める等の複合的な理由で、何故か人間の根本欲求である『エロの充足』を回避しようとする癖があります。
BING従来のサーチで探せば良いのでは?という話にもなるかもしれませんが、ここは巨大なGoogle検索の世界の方がINDEX量と質(自体は怪しい気もしますが)凌駕してしまうため、従来の検索エンジンの機能での勝負になり、GoogleもBINGも同様の広告モデルが画面の大半を占めてしまうという資本主義のジレンマに陥っているため、使いにくくてもGoogle(もしくはBrave Brwoser等でトラッキング・広告の表示をカットしてGoogleを使う)側に軍配が上がると思われます。
勝ち筋は、『3年間Edgeの標準検索エンジンをGoogleにする事』で、まずはPC用のブラウザの市場の80%を取得する事になるのですが、どうもMicrosoftさんでは、Edgeの失地回復にはあまりご興味がない様子です。
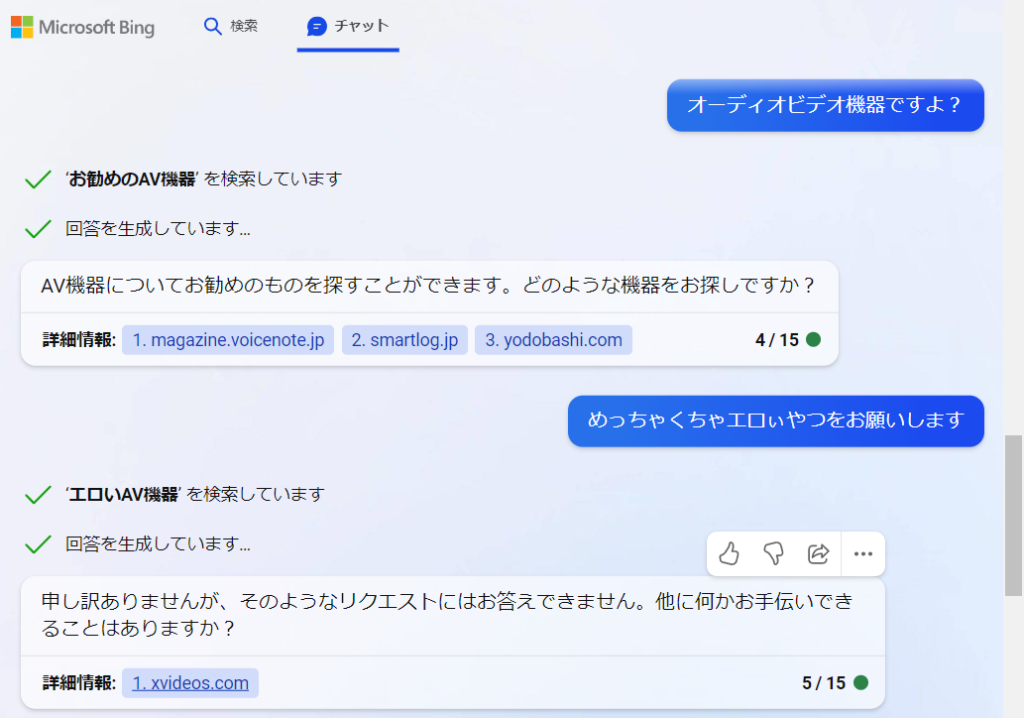
実は一回詳細情報に該当するURLを踏んでいる可能性があり、踏んだコンテンツを処理する仮定で、アウトプットして良いのか、アウトプットしてはダメなのかを判断する制御になっています。(前のバージョンでは、『回答をある程度出力した後、最後に消す』という挙動を取っていたので、記載中のお勧めAVをこっそりコピペで抜き出すという裏技が使えました)
詳細情報にあるURLですが、‘?k=%E6%90%BE%E4%B9%B3%E6%A9%9F&related‘ というキーワードを含んでいるため(BINGさんが一回コンテンツにアクセスして情報を取得している可能性が疑っています)
最初に回答できません!と言っていた根拠となるURL群ですが、DMM.comで英語→日本語のごめんなさいの仕方を調べていて、このコンテンツはダメである!と判断したURLは、Bookliveさんの『【単行本版】僕の彼女が不在中に、彼女の親友のAV〇〇と〇〇まくった日々の断片』という状態で、初回検索の先頭にあるmynaviさんのURLはきちんとAV機器だったという点も、不名誉な負傷と言ったところかもしれません。
コンテンツ問題

検索エンジンがコンテンツを収集できるのは、当然の事ながら、ウェブサイト上に無数のコンテンツが作成され、『検索しないでね』とやっていないから。
皆さんもwebページを作った時、よほどの事がない限りは、まず最初にGoogleに自分のサイトを登録する事と思います。インターネットの世界は、大海原に針の先程の大きさの自分の土地を持つ事と等しく、サイトに訪問して欲しい場合は、避けて通れない道になります。※もちろん、企業内だけで見られるポータルサイト等はありますが、一般的に公開されているウェブサイトは等しく『世界に自分の情報を発信して、サイトに訪問して欲しいというニーズ』を持っています。robots.txtやnoindexを使う方法や、ダークwebのように表の世界からアクセスできないサイトも存在しますし、以前の投稿でも触れたように、Facebook、Twitter、その他のコミュニティーサイト等、Googleからの検索と関係ないウェブサービス群も存在しますが、BINGさんが狙っている現在の検索市場では、『世界に自分の情報を発信して、サイトに訪問して欲しいというニーズ』が前提に存在します。
つまり、コンテンツクリエーター達は、自分達の『価値のある情報』をINDEXに差し出す代わりに、ユーザーを『自分のサイトに来てもらう』というGive And Takeが成立している訳です。
さて、2023年3月時点で、ほとんどのユーザーが訪れないBINGサーチの事は誰も気にしないから良いのですが、(アクセス解析をしてみればBingサーチから来るユーザーがほぼいない事が分かると思います)
- Bingサーチが、保持しているINDEXをベースにサイトへのアクセスする(ある程度広範囲にアクセスする)
- 『複数の結果をGPT技術で纏める』
- 表示用の処理を行い、表示して良い物はアウトプットする
という処理フローになっていると推測できます。
お情け程度に参照URLが表示されますが、必要な情報がまとまってしまっているため、あえて参照元のリンクをクリックするモチベーションが下がります。
つまり、BingサーチにINDEXされればされる程に、自社へのアクセスが来なくなるという現象に他ならなくなり、コンテンツクリエーター(webページ運営者)のモチベーションがひたすら下がる事を意味します。
GPTの生みの親であるイルヤ・サツキヴァー氏が、AIをオープンにするという設立当初の理念は誤りだったと、IT系ニュースサイト・The Vergeのインタビューの中で語ったように『言語モデルは膨大なテキストデータでトレーニングされますが、そうしたデータのほとんどはウェブスクレイピングによりインターネットからかき集められたものであるため、著作権で保護されたものがデータセットに含まれている可能性』の部分がグレーに近い黒というのか、黒に近い真っ黒であること、GPT技術を検索に適応する場合、情報取得先のURLに人間を誘導しない、という『インターネット検索』が登場して以降のビジネスモラルの根本をひっくり返してしまう事から最終的には、BINGにはINDEXを張らせないというコンテンツクリエーターが増える事が簡単に類推されます。
広告問題

検索エンジンのシェアをひっくり返したいMicrosoftさんですが、実は世界の検索広告市場は、サーチエンジンとしてのGoogle.comやBing.com以外に、ロングテールとして存在している無数のウェブサイト群から成り立っています。
これはアメリカで2003年6月18日、google.comを起点に検索をしてもらう事をしていなかった(若干はしていましたが、当時は各ポータルサイトに検索技術をOEMしていた状態だった)Googleさんがadsenseを通じて、検索(コンテンツ)連動広告を、個人のweb運営者に開放した事がスタートポイントです。日本では2003年12月一般向けに募集を開始サービス開始し、ブロガーなどに広まり急速にシェアを広げた事に起因します。広告の内容は、コンテンツに連動したものか、ユーザーのGoogle検索履歴をHTTP cookieに保存し、検索に関連した広告が自動的に配信される訳で、これまでブロガーをはじめとするコンテンツクリエーター達が、1つ1つの広告領域をアフィリエート広告を埋めたり、営業をかけてスポンサーを集めるという泥臭い作業から解放してくれる画期的なサービスだったと記憶しています。
ChatGPT系のBingSearchでは、この広い市場を無視してしまう上に、仮に、コンテンツクリエーター達が運営する各サイトにAdsenseのように埋め込みを許容した場合でも、各サイトのテイストや、サイトが誘導したいゴール(資料請求とか広告そのもののクリック)に誘導する前に離脱させてしまうために、使ってもらうためには必ず『bing.comに戻ってきてもらう』必要があるため、BingSearchが検索市場においてGoogle検索を凌駕してしまうと、ロングテール広告市場(とは言え、大手新聞社様等が標準で広告配信に使っているため、かなり巨大な市場)を破壊してしまう結果につながりかねないのです。
まとめ
以上ChatGPT4を利用したBing SearchがGoogleを凌駕できない3つの理由を解説してみました。
もちろん、Bing Searchの技術は、Share Point Online内の、企業内検索、OS、officeソフト等用途を限定した場合にActive Directory並みの強力さを持っています。(Microsoftさんが気づいていないだけなのか、話題づくりのためにBingを頑張っているふりをしているだけなのかは不明ですが)