

/
悲劇!これは私のAIじゃない!問題
AIブーム、DXブームの波に乗ったビジネスを10年近くやっていますと、POC終了間際・本番インプリ終了後、『これは私のAIじゃない』と怒り出すお客様が登場してきた思い出には事欠きません。
AI推進部門様は、この手の社内顧客(ビジネス部門)をあの手この手で納得してもらって、プロジェクトを進めていく訳ですが、AIその物に明確な定義がないために『私のAI』に関する解釈が揺らぎまくってしまっていたんだろうなという印象を強く感じる次第です。
人工知能学会様にも紹介されている、2016年に出版された書籍の解説にすら、人工知能の定義はまだない!と太文字で記載されている訳ですから、当時は、定義されていなかったのだと推測いたしている次第です。
じゃぁ、今AIとは、人工知能とは、を定義している皆様は…『オレオレAI』って言う事になっちゃうんでしょうか。
AIの気持ちになって表現すると
吾輩はAIである。 定義はまだ無い。 どこで生れたか頓と見當がつかぬ。 何でも薄暗い電算室で所で計算して居た事丈は記憶して居る。
民明書房『吾輩はAIである』より引用
という気分なんじゃないかと思います
ひとまず、個人的にはAIとはと言われたら、人工知能学会様の定義をお伝えするに留めて、『お客様ビジネス部門が本当に欲しい物』を探る旅からスタートするようにしています。
この過程で、8割近くの問題は、AIではない異なる解決が必要になる印象がありますが、ここでドロップ(案件提案停止)するのは無意味ですから、AI/DXを軸に、AI/DXでは解決できないビジネスプロセス、データフロー要素も含めて解決を試みる事がご提案の第一歩となります。
具体的には
にある、『様々な技術要素』に『AI以外で解決できない事象の解決施策』を組み合わせて、ビジネス上の問題を解決する』事が弊社の提供出来る最大の価値だと考えています。
それぞれの研究領域の対象範囲が奥深い事もあり、全技術を完璧に理解している人というのは存在しない状態なため、都度ベストな人材・組織と協力しながら課題の解決に寄与している次第です。
あのNTT DATAさんですら、2017年には
AI導入を検討する顧客企業のうち「費用対効果が出るとして実証に取り組むのは2割弱」と
https://xtech.nikkei.com/it/atcl/news/17/052601515/
と明かされていたので、相当奥深い問題なんだろうなと思っている次第です。
当時の私の経験上は、相談を受けた内実証に取り組む確率は30%位ではあったので、多少違和感はありましたが。
内50%はAIに行く以前の、データが紙問題とか違う問題だったのでした…
幸運なことに、AIバブル期は、あいまいな期待値を胸に、様々な企業様でPOCを開始していた状態でした。
AIベンチャー企業が雨後の筍ように生まれてきても彼らを十分に養えるだけのPOC数が発生していた状態でした。
成れの果てはPOC貧乏、POC死、PO死という言葉まで登場してしまったのがAIブームの終着点だったのでした。
精度が高い・低い問題が発生する3つの理由
やっとの思いで開始したPOCがPO死化していた理由に、精度評価問題があったと記憶しています。現在もデータサイエンティストの皆様は、ビジネス現場の皆様に『自分たちが作ったAIの精度が高いのか低いのか』のご説明に苦心されているのではないかと思います。
比較的コストが張るAIの評価には、作って良かった!と言う合意形成が難しい印象があります。そのため、ブレイクスルーするために、モデル評価方法として広く使用されている混同行列を活用して説明しよう!と言う流れになるのが一般的です。
しかし、ひとたびこの『混合行列』もしくは、「正解率(Accuracy)」「適合率(Precision)」「再現率(Recall)」「F値」の値を使い始めた瞬間、、、ビジネスユーザー側が、混同から、錯乱(本来のcofusionの意味)し始めます。
そうでなくても、文系の皆さんの人間の脳みそは3次元※の事象は考えられない構造になっているので混同ではなく錯乱し始める訳なのです。
これはAIがどんなに流行しても、決定木、RFMの内RFしか使わないとかRMしか使わない現象と似ていたりします。ビジネス部門にこの予測結果がなぜ導き出されたかを、数式を用いずに説明する方法がなかなか見つからない事にも起因するのではないかと思っています。
酷い事に、多くのデータサイエンティストの皆様も、話ているうちに言い間違えが始まり、錯綜から錯乱に突入して、会議時間の9割が『精度とは』になり、精度問題が落ち着くまでの数回のセッションは、ずっと同じ説明をし続ける事になったりします。
正直、sklearn.metrics.confusion_matrix で値を出して、変な事になっていないかを確認する程度だと思うので、それもそうなんですけどね
また、GoogleのAIが囲碁の世界チャンピオンを打ち負かしたりする事もあって、AIの予測精度を『平均値をちょっと良くした物』と思わず、将来が100%予想できてしまうと言うビジネスサイドの期待値もあることもあるのかもしれません。
※注釈:混同行列はそもそも3次元じゃない!予測と実績の2次元しかない!と言うお叱りを受けそうなのですが、2次元の割に大混乱が起きるのですが、どうしてここまで混乱が発生してしまうのでしょうか…
confusion matrix説明すればするほど現場は錯乱
だいたい、めんどくさいのと絵がかわいいのもあって、説明には下のリンクが使われることが多い印象があります。
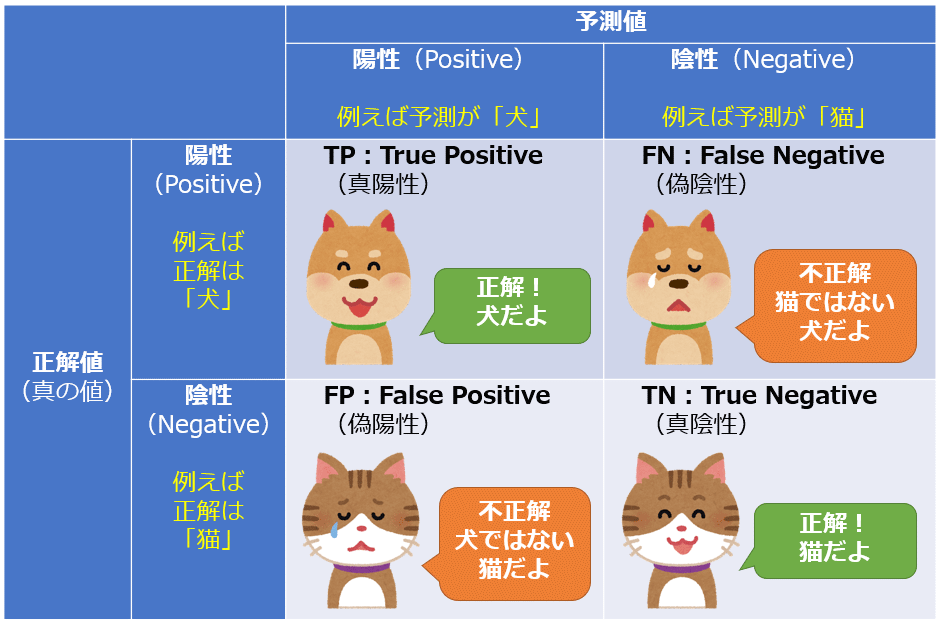
かわいいのは事実ですし、理解している人が読めば、理解可能なのですが…説明内にTPやら、下みたいな説明が出てきて、説明内の単語のおかげで何がなんだか分からなくなり始める訳です。
1行1列目はTP(True Positive:真陽性)=正解値が陽性(Positive)で、予測値が陽性(Positive)なので、正解(True)
1行2列目はFN(False Negative:偽陰性)=正解値が陽性(Positive)で、予測値が陰性(Negative)なので、不正解(False)
2行1列目はFP(False Positive:偽陽性)=正解値が陰性(Negative)で、予測値が陽性(Positive)なので、不正解(False)
2行2列目はTN(True Negative:真陰性)=正解値が陰性(Negative)で、予測値が陰性(Negative)なので、正解(True)
日常利用する単語の中に、真陽性とか、偽陰性とか、偽陽性とか真陰性とか…考えませんよね?
また、順番にしても、予測した物が当たっていたか外れていたかの2次元でしか考えられないのに、正解値がから入ってしまうので、どうしてもビジネスサイドは何を言われてるのか分からなくなってしまうのです。
ここは下のように説明しないと、話がごちゃごちゃになってしまう訳ですね。(学術的に正しいか否かは別のお話です)
- AIがYESと予測した物の内、正解の物、不正解の物
- AIがNOと予測した物の内、正解の物、不正解の物
| 結果↓ 予想→ | 予想YES | 予想NO |
|---|---|---|
| 結果YES | 予Y・結Y | 予N・結Y |
| 結果NO | 予Y・結N | 予N・結N |
| 結果↓ 予想→ | 予想YES | 予想NO |
|---|---|---|
| 結果YES | 予Y・結Y true positive(当たってる YESと言う予測値) | 予N・結Y false(外した) NOという予測 |
| 結果NO | 予Y・結N false (外れている) YESという予測値 | 予N・結N true(当たっている)NOという予測 |
真=TRUE(正解)の陽性という予測
偽=false(間違っている)の陰性という予測
偽=False(間違っている)の陽性
真=TRUE(正解)の陰性と言う予測
と言う事象なんですよね。
つまり、Confusion(混同)が本当のConfusionを生み出している訳でした
形容詞の性質もあるのかもしれませんけど、文系の人間の考える順序と異なるので、説明がこんがらがるのも無理はない話ですよね
ここまでの説明を書くのに4時間位考えたので、多分、ビジネス現場に正しく理解してもらおうとするのは、至難の業なんだと思います。
「正解率(Accuracy)」
予測対象数で、正解した回答の数を割った物になりますね
ざっくり言うと、全部をYES/NOと予測させて、結果があっていた物の割合と考えれば、大きく外しはしていません。
| 結果↓ 予想→ | 予想YES | 予想NO |
|---|---|---|
| 結果YES | 予Y・結Y | 予N・結Y |
| 結果NO | 予Y・結N | 予N・結N |
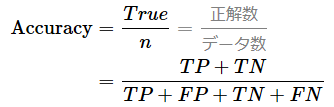
「適合率(Precision)」
やっかいさの生みの親、Precision
この言葉は、統計学・科学における専門的な用語の世界では、「正解率(accuracy)」と「精度(precision)」は明確に区別されるというさらなる錯乱ポイントです。さらにやかいな事に、このPrecisionには、精密さ、精密度、精度という呼び名があるため日本語で使われる『精度』と異なる特性(数式で定義されている物)が出てしまうため、混乱に混乱を呼び起こす状態になります。
もう、めんどくさいので、Precisionとして憶えてしまって、いっその事分析者の皆さんは『精度』という言葉は放念してくださいと思う時はしばしばで、さらに、分析者の皆さんも、日本語としての精度と専門用語での精度をごっちゃごちゃにして使う事が多いので、もう話しがかみ合わない事必至です。
ちなみに、Precisionですが、予測値の内、YESとした物の数で、実際の正解数を割る方法になります
| 結果↓ 予想→ | 予想YES | 予想NO |
|---|---|---|
| 結果YES | 予Y・結Y | 予N・結Y |
| 結果NO | 予Y・結N | 予N・結N |
「再現率(Recall)」
結果がYESだった総数で、予想YESを割った値。
うち漏らしを少なくする上で重要になります。
| 結果↓ 予想→ | 予想YES | 予想NO |
|---|---|---|
| 結果YES | 予Y・結Y | 予N・結Y |
| 結果NO | 予Y・結N | 予N・結N |
特異度 Specificityという指標もありまして…
こちらは、再現率と表裏一体になっているような値です。
| 結果↓ 予想→ | 予想YES | 予想NO |
|---|---|---|
| 結果YES | 予Y・結Y | 予N・結Y |
| 結果NO | 予Y・結N | 予N・結N |
「F値」
PrecisionとRecallがトレードオフの関係にあるために双方のバランスを取るために考案された精度検証方法
ビジネス側のこの話をする段階で、負け
問題を乗り越えるたった一つの方法
実はこの問題を乗り越える方法は、本当に1つだけで、精度の検証方法を初回のミーティングで合意しておく
と言う事だけなのでした。
つまり、「正解率(Accuracy)」「適合率(Precision)」「再現率(Recall)」の3つの中から、全数のデータと予測対象の数を確認した上で、ビジネス部門さんが、どの値重視しているかを確認し、どのスコアを精度として伸ばしていくのかと言う点で合意すれば問題が氷解するのでした
評価指標は、プロジェクトの序盤で認識合わせしておいた方が良いと言うのが必要事項で、この事は混同行列に限った話ではないので、性能評価全般で言えることだと考えています。
ぐでぐでと長文を書いておいて、ほんとこれだけかい??ってお話ですが、びっくりする位に精度検証問題があっさりクリア可能になりますので、騙されたと思って試してみてください
逆にこのステップを踏まないと、毎回精度検証、評価フェーズで炎上する事間違いなしだと思います
何故って、ビジネス現場が思う程、精度って高く出ないからです。(評価指標上です)
実際予測結果をビジネス適応していただくと効果は出る事が多いので(出ない時もある)、AIを使ったPOCは、ビジネス適応計画も含め、プランニングにしっかり時間とお金をかける事も重要だと痛感する次第でした。